Zastoupení webových vyhledávačů
Internetové vyhledávače v ČR
V České republice máme dnes dva důležité vyhledávače – americký Google a český Seznam. Česká republika tak patří k pouhým čtyřem zemím na světě, kde se zatím lokálnímu vyhledávači daří Googlu odolávat. Dále se tu používají vyhledávače Bing (patřící Microsoftu), Yahoo a ruský Yandex, ale ty se společně dělí o jednotky procent vyhledávání.

Proč se u nás vyhledávač Seznam udržel tak dlouho, tomu asi rozumí málokdo. Provoz webového vyhledávače je velice náročná disciplína – kromě zmiňované obrovské výpočetní síly jsou potřeba také velké investice do inovací, kvalitní tým a neuvěřitelný tah na bránu. Jakmile vyhledávač začne ve vývoji zaostávat, jeho uživatelé rychle přejdou ke konkurenci. Takto v historii zemřela celá řada vyhledávačů, z těch českých například Morfeo či Jyxo.
Seznamu se však přesto dlouhodobě dařilo držet s Googlem krok a oba internetové vyhledávače si dělily trh přibližně půl na půl.
Změnil to až nástup mobilních zařízení po roce 2008. Vyhledávač Google se na to dobře připravil a vytvořil vlastní mobilní operační systém Android, který nabídl výrobcům telefonů. Ten pochopitelně k vyhledávání na internetu používá právě Google. Od té doby Seznam ztrácí.
Kolem roku 2020 držel Google už přibližně 76 % hledání, Seznam pak 24 %. Každý další rok však ztrácí Seznam přibližně 3 % podílu. V roce 2024 už má Seznam jen 12 %, Google vyrostl na 81 % a Bing vyrostl na 4 %.
Webové vyhledávače v zahraničí
V zahraničí jasně vede vyhledávač Google, který si ve většině zemí ukrajuje 90–95 % vyhledávání. O zbytky se pak dělí hlavně vyhledávače Bing a Yahoo. K výjimkám, kromě již zmíněné České republiky, patří tři další země:
- Čína, jíž dominuje vyhledávač Baidu s přibližně 70 % hledání
- Rusko se svým Yandexem s cca 62 % hledáními
- Jižní Korea s místním vyhledávačem Naver, který ovládá asi 70 % trhu místního vyhledávání
E-book za mail
Získejte podrobný návod Jak na e-mail marketing (52 stran). Více informací.
Žádný spam, jen užitečný obsah. Newsletter posílám cca 8× ročně. Odhlásíte se kdykoliv.
Další velké internetové vyhledávače
Pokud bychom si internetový vyhledávač definovali obecněji, tj. jako program sloužící pro vyhledávání informací na internetu a nesledovali pouze fulltextové vyhledávání internetových stránek, pak by bylo třeba zmínit ještě další vyhledávače. Pro ČR bohužel nemám údaje o poměrech hledání, tak si musíme vystačit s daty z USA z roku 2018:
- Google Images – vyhledávání obrázků ve vyhledávačí Google (v USA má asi 22 % všech hledání)
- YouTube – největší vyhledávač videí na světě, nepočítaje v to pornografické weby (v USA asi 4,3 % hledání)
- Amazon – vyhledávání zboží (v USA asi 2,3 % hledání)
- Facebook – vyhledávání kontaktů a dalšího obsahu této sociální sítě (v USA 1,4 %)
- Google Maps – hledání míst na mapách po celém světě (1,3 % vyhledávání v USA)
- Pinterest – sociální síť, na které lidé hledají obrázky (0,5 % hledání)
Vyhledávače nás ovlivňují
Jak často vyhledávače používáme
Bez vyhledávačů už si dnes lze život jen těžko představit. Fungují jako neomezená brána do internetového světa informací. Podle analýzy nástroje Marketing Miner na datech roku 2019 položí Češi přibližně 800 000 000 až 1 miliardu dotazů měsíčně vyhledávači Google a 210 000 000–300 000 000 dotazů vyhledávači Seznam. Jde o čísla týkající se čistě fulltextového vyhledávání, tedy nikoliv vyhledávání obrázků, videí apod., která by počty hledání dále významně zvyšovala.
To znamená, že každý obyvatel ČR, který je aktivní na internetu (což je podle Českého statistického úřadu asi 6,2 milionu lidí) položí některému z webových vyhledávačů asi 186 dotazů měsíčně. To je obrovské číslo, nezdá se vám? Na schopnostech vyhledávačů jsme dnes prakticky závislí.
Nastavení výchozího vyhledávače
Naše závislost na vyhledávačích jim dává obrovskou moc – vyhledávače (společně se sociálními sítěmi) zásadně ovlivňují, jaké jaké informace se k nám dostávají a jak vnímáme svět. Proto také Evropská unie pod hrozbou miliardových pokut tlačí na zmenšení monopolu Google a snaží se ho přinutit k tomu, aby do svého ekosystému (na prohlíži Chrome či na operačním systému Android) pustil i konkurenční vyhledávače.
A Google, až nerad, ustupuje. Na prohlížeči Chrome si tak můžete nastavit i jiné vyhledávače. Dělá se to kliknutím na tři tečky (menu) v pravém horním rohu. Vyberte možnost „Nastavení“ a zde si pak v sekci „Vyhledávač“ můžete nastavit vyhledávač používaný v adresním řádku a další vyhledávače, které bude prohlížeč používat.
Jak funguje webový vyhledávač
Vyhledávání na internetu zahrnuje šest postupných kroků:
- Crawling – roboti vyhledávače se procházejí po internetu, hledají nové stránky a znovu navštěvují ty staré, které mezitím mohly být aktualizovány.
- Indexing – obsah jednotlivých stránek si vyhledávač ukládá do tzv. indexu, do své obrovské databáze informací.
- Ranking – vyhledávač uložené stránky hodnotí podle mnoha set faktorů a sleduje jejich vztah k různým tématům.
- Query understanding – uživatelé vyhledávače mu pokládají dotazy a vyhledávač se jim snaží co nejlépe porozumět.
- SERP – vyhledávač zobrazuje nejrelevantnější odkazy a další odpovědi v podobě tzv. výsledků vyhledávání.
- PPC – vyhledávač do výsledků vyhledávání přibaluje také inzeráty placené reklamy a tím je monetizuje.
Procházení webu (crawling)
O plnění databáze vyhledávače se stará tzv. crawler (neboli robot). U Google se mu říká Googlebot, u Seznamu je to Seznambot. Je to speciální program, který prochází webové stránky pomocí hypertextových odkazů.
Může se stát, že robot vyhledávače na web vůbec nechodí. Ověřit to lze nejlépe pomocí serverových logů. Nejčastěji to bývá tím, že:
- web není uzpůsobený k tomu, aby ho mohl robot procházet
- robot vyhledávače má procházení zakázané, obvykle v souboru robots.txt
- jde o úplně nový web, o němž vyhledávač ještě neví – ještě na něj nevede žádný odkaz a vyhledávač jsme na něj sami nijak neupozornili
Jak robot vyhledávače stránky prochází
Roboti stránky procházejí podle principu náhodného klikače, tzn. že více navštěvují stránky významné a méně chodí na weby nedůležité. Na všechny stránky se však postupně vrací, aby zjistili případné změny a databázi vyhledávače průběžně aktualizovali.
Na každý web má robot omezený rozpočet, tzv. crawl budget, který říká, kolik času je na webu robot ochotný strávit. Čím je web z pohledu vyhledávače důležitější, tím má crawl budget větší.
Indexace stránek
Během procházení stránek si vyhledávač web indexuje. To znamená, že si jednotlivé stránky ukládá do své databáze. Mám pocit, že Google odděluje indexování a hodnocení stránek do dvou kroků. Při první návštěvě robot stránku objeví a uloží do indexu a při druhé návštěvě ji ohodnotí. Vyhledávač Seznam to, tuším, dělá oboje najednou.
Stejně jako procházení, i indexování stránky či dokumentu může majitel webu vyhledávači zakázat. Pro stránky se to dělá pomocí meta tagu robots, pro dokumenty, do kterých nelze umístit meta tag, to děláme pomocí HTTP hlavičky X-Robots-Tag.
Ověřit si, zda webový vyhledávač váš web indexuje, si můžete nejsnáze vyhledáním dotazu na způsob „váš brand site:vase-domena.cz“. Já bych třeba hledal „štráfelda site:strafelda.cz“. Vyhledávač tedy hledá všechny stránky, které obsahují „štráfelda“ a nachází se na doméně „strafelda.cz“ (to dělá ono „site:“). Přesnější čísla pro Google vám pak dá příslušný přehled v nástroji Search Console, který vyhledávač poskytuje majitelům webů zdarma.
Jak probíhá indexace vyhledávačem
Do indexu se nedostane každá stránka, kterou roboti vyhledávačů objeví. Vyhledávače se pochopitelně zajímají hlavně o unikátní informace. Často se však stejný obsah nachází duplicitně na více různých adresách, ať už na jednom webu, nebo na více doménách. Vyhledávač si obvykle vybere jednu z nich. To je jedním z důvodů, proč se e-shopům nevyplácí přebírat popisky či fotky produktů od dodavatele a proč by si měli vytvářet vlastní.
Aby si mohl vyhledávač stránku naindexovat, potřebuje správně rozpoznat její jazyk. To dělá hlavně pomocí heuristické analýzy, kdy v textovém obsahu stránky vyhledává typická slova pro daný jazyk. A dále se dívá na indikátory přímo v HTML kódu, jako je parametr lang a také hreflang, speciální HTML element, kterým vývojáři v hlavičce stránky označují jazykové mutace. Nebo na doplňující informace v souboru sitemap.xml.
Hodnocení stránek (ranking)
U každé nalezené stránky se internetový vyhledávač snaží zjistit, o čem stránka je a na které dotazy uživatelů by byla relevantní odpovědí. Říká se tomu ranking. Vyhledávače dnes stránku hodnotí nejméně podle vyšších stovek kritérií, tzv. faktorů. Ty se dělí na tzv. on-page (týkající obsahu stránky) a off-page faktory (týkající se odkazů na danou stránku). V posledních letech přibyly k SEO faktorům také tzv. uživatelské signály, jako je například míra prokliku z výsledků vyhledávání, dwell time nebo Core Web Vitals.
Algoritmy vyhledávačů
Způsobu, jak vyhledávače stránky hodnotí, se říká vyhledávací algoritmus. Přesné algoritmy vyhledávače pochopitelně nezveřejňují, odhadujeme je pouze na základě experimentů, analýz a oficiálních doporučení vyhledávačů. Vyhledávací algoritmy, i když jejich principy zůstávají stejné již desítky let, se neustále vyvíjejí. Například v roce 2018 udělal vyhledávač Google 3 200 úprav svého algoritmu. Jen pro zajímavost, v roce 2009 to dělalo pouze asi 400 změn. Tempo vývoje vyhledávačů se stále zrychluje.
Velkým změnám algoritmu, které mají dopady na mnoho hledání, říkáme updaty. Vyhledávač Google je s oblibou pojmenovává po zvířatech – Panda, Penguin (tučňák), Pidgeon (holub), Hummingbird (kolibřík)… Takovým updatem je také známý RankBrain, založený na strojovém učení.
To mi připadá hodně zajímavé, že dnes už přesným algoritmům internetových vyhledávačů nerozumí ani sami jejich tvůrci. Právě proto, že vyhledávače masivně využívají strojové učení, které samo navrhuje optimální algoritmy a váhy jednotlivých faktorů tak, aby vyhledávač dosáhl nejlepších výsledků. Ty se definují například pomocí ručního hodnocení.
Jak si vyhledávače vytváří databázi stránek: 1) Crawling – roboti prochází stránky. 2) Indexace – stránky si vyhledávač ukládá do indexu. 3) Ranking – vyhledávač stránky hodnotí podle stovek faktorů.
Přidat na X jedním klikem Sledovat autora na platformě XVyhledávací dotazy
Druhy dotazů
Uživatelé vyhledávače se ho průběžně ptají na hledané informace, tj. pokládají mu tzv. vyhledávací dotazy. Ty se dělí na čtyři skupiny:
- informační dotazy – uživatel vyhledávače hledá odpověď na konkrétní otázku
- transakční dotazy – uživatel vyhledávače chce něco koupit či objednat
- navigační dotazy – uživatel vyhledávače se potřebuje někam dostat
- připojovací dotazy – dotazy pokročilých uživatelů vyhledávače, například hledání s omezením na jednu doménu
Proč marketéři potřebují znát klíčová slova
Znalost vyhledávacích dotazů, které lidé vyhledávači pokládají a které se zároveň týkají našeho oboru podnikání, je pro nás marketéry naprosto zásadní. To proto, že nám:
- Pomáhá porozumět cílovým skupinám, umožňuje nám pochopit jejich motivace a způsob, jak o daných produktech či službách přemýšlejí, jak je pojmenovávají atd.
- Umožňuje zjistit, na jaká témata máme na webu vytvářet obsah, jaké fráze v takových textech je třeba používat a které z těchto frází mají prioritu (trhání nízko visícího ovoce).
Vyhledávacích dotazů je však i v nových oborech spousta a často se liší jen málo, třeba slovosledem či diakritikou. Ve skutečnosti nás tedy zajímají tzv. klíčová slova, což jsou vyhledávací dotazy očištěné o překlepy, duplicity a další podobnosti. Zjišťujeme je pomocí analýzy klíčových slov.
Jak webový vyhledávač s dotazem pracuje
Přesné postupy pochopitelně vyhledávače tají, ale předpokládá se, že vyhledávač zadaný vyhledávací dotaz nejdříve upravuje – odstraní z něj tzv. stop slova, (spojky a další slova bez významu), ostatní slova lematizuje (převede slova na jejich základy).
Takto upravený dotaz pak vyhledávač porovná se svým indexem na základě složitých vzorců počítačové lingvistiky. Pravděpodobně jde o nějakou kombinaci tzv. bigramů (dvojic slov, které mají vzájemnou syntaktickou vazbu), s unigramy (jednotlivými slovy v dotazu), s přihlédnutím k synonymům daných slov. Některá slova také vyhledávače zřejmě chápou jako entity, u kterých dokážou vnímat vztahy k jiným entitám (třeba autor ↔ dílo). Výsledkem je, že uživatel dostává odpověď na téma svého hledání a nikoliv na přesnou frázi.
Personalizace výsledků vyhledávání
Protože vyhledávání pouze podle aktuálního dotazu uživatele může být málo přesné, vyhledávače hledají i podle mnoha dalších indicií, které kontext doplňují. Známý je tím zejména Google, který hledá:
- podle země a jazyku uživatele
- podle přesné lokality, kde se nacházíme
- podle toho, zda hledáme z mobilního telefonu či z počítače
- podle informací, které o nás má tím, že jsme přihlášení ke Google účtu
- podle historie našich předchozích hledání
Jedním z důsledků personalizovaného hledání je, že nelze jednoduše ověřovat umístění webu ve výsledcích tím, že si do vyhledávače zadáme příslušné klíčové slovo a podíváme se, jak náš web vypadává. My ho můžeme vidět na prvním místě, ale většina uživatelů ho třeba vůbec neuvidí.
Potřebujeme-li tedy znát pozice webu ve výsledcích vyhledávání, je třeba sáhnout po specializovaných nástrojích. A počítat s tím, že i ty zobrazují jakási průměrná, orientační čísla.
Search intent
Podle vyhledávacího dotazu, historie hledání, lokality a dalších parametrů se webový vyhledávač poukouší odhadnout záměr, se kterým uživatel vyhledává – tzv. search intent. To proto, že v mnoha případech pokládáme totožný dotaz, ale chceme rozdílné výsledky – někdy o dané věci chceme zjistit více informací, jindy si ji chceme přímo objednat, potřetí třeba hledáme konrétní článek, který už jsme četli dříve a víme, že o dané problematice výborně píše.
Search intent je tak dalším zásadním důvodem, proč webové vyhledávače poskytují personalizované vyhledávání. A zároveň je jeho znalost naprosto zásadní pro marketéry, SEO specialisty a tvůrce obsahu – například se ani se sebedokonalejším informačním článkem ve vyhledávači neprosadíte u lidí, kteří si chtějí produkt zakoupit.
Výsledky vyhledávání
Stránkám, které vyhledávač vrací na položený dotaz, se říká výsledky vyhledávání. Setkat se můžete také se zkratkou SERP (search engine result pages). Skládají se z neplacených výsledků vyhledávání, které vznikají výše uvedeným postupem, tj. tím, že robot prochází stránky a indexuje je. Ty pak vyhledávač doplňuje o reklamu, tzv. placené výsledky vyhledávání a o další widgety (například mapy, karusely s obrázky, Knowledge Graph apod.).
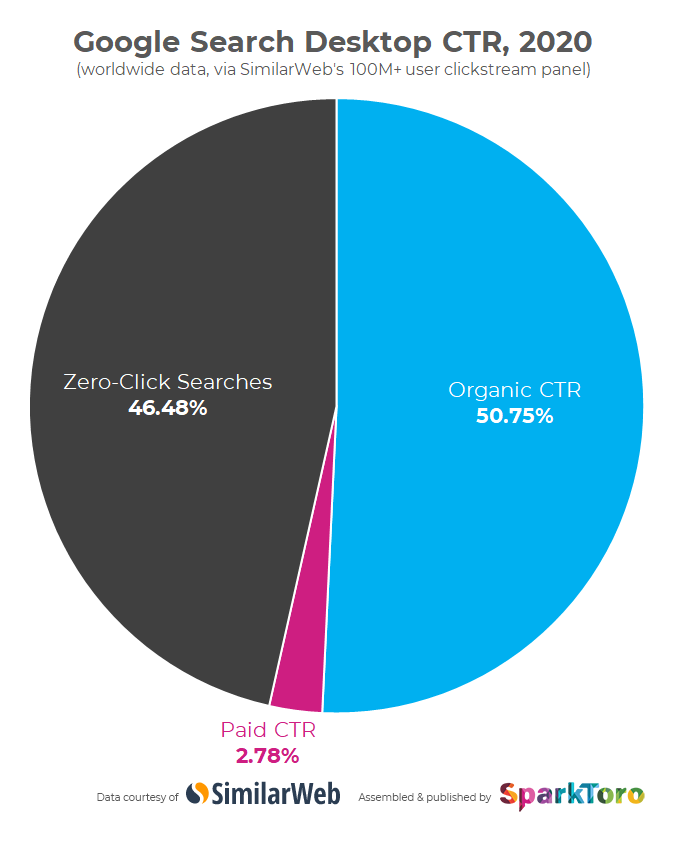
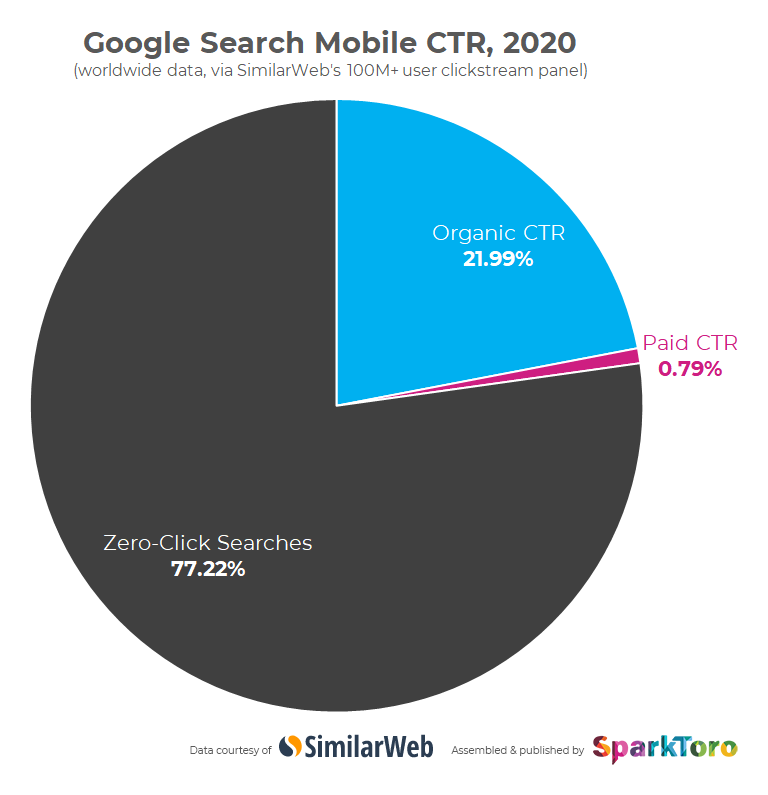
Neplacené výsledky vyhledávání
Neplaceným výsledkům vyhledávání se také říká přirozené či organické, v měřících nástrojích proto tento marketingový kanál najdete jako organic. Skládají se z jednotlivých odkazů, které vyhledávač doporučuje jako nejrelevantnější odpověď na dotaz. Těch bývá sedm až deset na stránce.
Každý odkaz je tvořený třemi či čtyřmi důležitým prvky:
- Výrazným nadpisem, který vyhledávač přebírá z titulku stránky, či od roku 2021 také z některého nadpisu, nebo si ho generuje sám.
- Pod ním následuje popisek, kterým je buď obsah meta tagu description, nebo nějaký úryvek z textů na stránce – záleží na tom, co vyhledávač považuje za lepší odpověď.
- Nad nebo pod popiskem se pak zobrazuje URL adresa odkazu, obvykle zkrácená, někdy v podobě drobečkové navigace.
- V poslední době vyhledávače zobrazují také ikonky webu, tzv. favicon.
Někdy vyhledávač zobrazuje u odkazu i další informace, napřílad sitelinky či odkazy vedoucí do obsahu dané stránky. Jindy zde najdete i tzv. rich snippety, které výše popsanou podobu odkazů rozšiřují a umí k nim přitáhnout více pozornosti. Všechny tyto doplňky značně zvyšují míru prokliku. Google používá také tzv. vybrané úryvky (featured snippets), které mají míru prokliku zásadně vyšší, protože jsou ve výsledcích umístěny na prvním místě a navíc mnohem více zvýrazněny.
V organických výsledcích velice záleží na pořadí, protože první odkaz získává významně více prokliků (cca třetinu až polovinu) a i druhý odkaz má stále několikanásobně více prokliků než trojka. Na další stránky výsledků už chodí pouze 2 % uživatelů – pokud nás první stránka neuspokojí, většinou raději dotaz přeformulujeme jinak.
Víte, jaké je je nejlepší místo, kam ukrýt mrtvolu? Druhá stránka výsledků vyhledávání. Tam chodí jen 2 % uživatelů. #SEO #SERP
Přidat na X jedním klikem Sledovat autora na platformě XPlacené výsledky vyhledávání
Placeným výsledkům vyhledávání se také říká sponzorované. Jsou to inzeráty placené formou PPC, které vyhledávač zobrazuje nad a v některých případech i pod organickými výsledky. Graficky se placené výsledky velmi podobají výsledkům přirozeným (což je pochopitelným záměrem vyhledávače). Jen u nich vyhledávače zobrazují kromě sitelinků i různá další rozšíření (telefonní čísla, adresy apod.). Placené výsledky poznáte podle malého zeleného nápisu „reklama“ (v angličtině „ad“).
Doplňující widgety
Obecně platí, že se vyhledávače snaží co nejvíce dotazů uživatele odpovědět rovnou ve výsledcích vyhledávání. Takovým dotazům se říká zero-click searches a jejich poměr vůči ostatním dotazům stále stoupá. Aktuálně jsou to asi dvě třetiny všech hledání, což je obrovské číslo. To je nepříjemné hlavně pro tvůrce obsahu, protože uživatel vyhledávače k nim vůbec nepřijde na web. A oni s ním tedy vůbec nemohou nijak pracovat (zobrazit mu reklamu, něco mu prodat).
Typickým příkladem může je počasí – třeba na dotaz „počasí praha“ vyhledávač Google zobrazí obrovský panel s týdenní předpovědí, aktuálním počasím, srážkami a rychlostmi větru. Proč by tedy uživatel vyhledávače chodil na web o počasí? Takto vyhledávače postupně kanibalizují stále více oborů. Více k tomu píšu na stránce Výsledky vyhledávání.
Jak se chováme ve výsledcích vyhledávání
Podle studie SparkToro z července 2024, když zadáme dotaz do Google:
- 37,4 % uživatelů neudělá nic (zřejmě odpověď zjistí přímo z výsledků).
- 30 % uživatelů klikne na organické výsledky vyhledávání.
- 22,3 % uživatelů dotaz přeformuluje a zadá znovu.
- 9,7 % uživatelů klikne na odkaz na některý z webů provozovaných Googlem (Google Maps, YouTube apod.)
- 0,6 % uživatelů klikne na placenou reklamu.

Marketing ve vyhledávačích
Z výše uvedeného je zřejmé, že vyhledávače jsou pro webové stránky a aplikace velice důležitým zdrojem návštěvnosti. Získáváním, zvyšováním a kultivací této návštěvnosti se zabývá obor zvaný marketing ve vyhledávačích, známý pod zkratkou SEM (search engine marketing).
Ten se dále rozděluje na dva podobory, které spolu ale blízce souvisejí – optimalizaci pro vyhledávače (která řeší organické výsledky vyhledávání) a PPC reklamu, která se zabývá placenými výsledky.
Optimalizace pro vyhledávače
Optimalizace pro vyhledávače, známá i pod zkratkou SEO (search engine optimization) je obor na pomezí mnoha jiných oborů. Skvělé SEO je především otázkou strategie a taktiky. Stejně jako u jiných marketingových kanálů potřebujete oboru rozmět, dobře si naplánovat kroky, nastavit si cíle a také způsob, jak budete optimalizaci pro vyhledávače měřit (KPI). Také je třeba chápat SEO v kontextu dalších marketingových kanálů, protože lidé před nákupem přicházejí na web opakovaně, z různých zdrojů. A vyhledávače obvykle konverzní cesty otevírají. Tohle všechno by vám měl umět vysvětlit váš SEO konzultant.
Za druhé je třeba optimalizovat samotný web, aby byl pro roboty vyhledávačů přístupný, aby mu rozuměli, aby se jim líbil a stránky získávaly vysoké hodnocení. Tento krok je ideální udělat ještě před vytvořením webu, tj. web rovnou navrhovat s ohledem na vyhledávače. Struktura webu, navigace, výběr redakčního systému, rychlost webu – tyto a mnohé další faktory ovlivňují umístění ve výsledích vyhledávání. A těžko je napravovat zpětně. Sem spadá i tzv. technické SEO.
Za třetí potřebujete spoustu zpětných odkazů, podle kterých vyhledávače poznají, že máte na webu unikátní a užitečný obsah, který by měly dále doporučovat. Bez důkladného linkbuildingu se v konkurenčnějších segmentech neobejdete. A v neposlední řadě, pochopitelně, potřejete ten báječný obsah. Optimalizace pro vyhledávače je úzce spojená s content marketingem, jehož výstupy ale využijete i v jiných kanálech. A jsme zpátky u té strategie a nutnosti vše měřit a průběžně cíle vyhodnocovat.
PPC reklama
Představte si, že jste autory známého a hojně používaného vyhledávače ![]() Máte k dispozici neuvěřitelně hodnotný reklamní prostor, kde se navíc zákazníci vašich inzerentů sami segmentují podle položených dotazů. Jak byste z výsledků vyhledávání vytěžili co nejvíce peněz tak, aby to bylo dlouhodobě výhodné pro vás i pro inzerenty? Dává smysl prodávat tento prostor formou PPT, tj. pronájmem za určitý čas („na měsíc ti tam šoupnu banner“)? Nebo formou PPV, tj. prodávat určitý počet zobrazení bannerů za fixní částku („za tisícovku se ti banner zobrazí 500ד)?
Máte k dispozici neuvěřitelně hodnotný reklamní prostor, kde se navíc zákazníci vašich inzerentů sami segmentují podle položených dotazů. Jak byste z výsledků vyhledávání vytěžili co nejvíce peněz tak, aby to bylo dlouhodobě výhodné pro vás i pro inzerenty? Dává smysl prodávat tento prostor formou PPT, tj. pronájmem za určitý čas („na měsíc ti tam šoupnu banner“)? Nebo formou PPV, tj. prodávat určitý počet zobrazení bannerů za fixní částku („za tisícovku se ti banner zobrazí 500ד)?
Samozřejmě, že nic z toho. Vyhledávač zobrazuje spousty výsledků vyhledávání na nejrůznější dotazy, přičemž každý takový výsledek má pro inzerenty úplně jinou hodnotu. Záleží na ceně zboží – jinou cenu má být viděn na frázi „kde koupit luxusní bmw v praze“ a úplně jinou na „pizzerie v praze“. Cena se také bude lišit podle toho, v jaké fázi nákupního cyklu se potenciální zákazník nachází. Mnohem nižší cenu bude mít fráze „jak vybrat zrcadlovku“ než fráze „canon eos 1200 recenze“, u které už je zákazník vyhledávače zřejmě těsně před nákupem. Ve výsledcích vyhledávání budete mít samozřejmě i stránky, na kterých se reklamní prostor prodat vůbec nedá (třeba „kdy se narodil beethoven“).
Ano, řešením je každé takové reklamní nice určit jinou cenu. Jenže jakou, jak poznáte, kde přesně vede tržní hranice? Jako vyhledávač chcete maximalizovat zisk z daného prostoru. Hranice pro danou stránku navíc nebude pevná, bude se měnit třeba podle sezóny, podle aktuální konkurence v oboru atd. Víte, co s tím? Jasně, necháte zákazníky, aby každou takovou reklamní niku sami ohodnotili. A předposlední otázka – stále se vžívejte do pozice majitele oblíbeného vyhledávače – jak zajistíte, že inzerent cenu nepodstřelí, že opravdu přijde s nejlepší možnou nabídkou? Už víte? Dobře vy! ![]() Řešením je aukční model. Necháte jednotlivé zákazníky přihazovat a prostor pak poskytnete jen těm nejvýnosnějším.
Řešením je aukční model. Necháte jednotlivé zákazníky přihazovat a prostor pak poskytnete jen těm nejvýnosnějším.
A finální, bonusová otázka na závěr: komunikace se všemi těmi zákazníky by si vyžadovala obrovské množství zaměstnanců a obchodních zástupců, kteří by jen telefonovali a nastavovali reklamní kampaně. A stejně by se to všechno nedalo dělat v reálném čase. Jak to jako majitelé vyhledávače vyřešíte? Přesně tak – přenesete tento náklad na inzerenty, tj. poskytnete jim webové rozhraní, aby si své inzeráty mohli spravovat sami.
Proto mají vyhledávače reklamní systémy, Google má svůj Google Ads (dříve Google AdWords) a Seznam svůj Sklik. Inzerenti zde nabídnou, kolik jsou ochotní zaplatit za proklik a vyhledávač jim po přivedení návštěníka příslušnou částku strhne. Případně nižší, když zrovna dotaz není konkurenční. Zároveň si tu inzerent může sám spravovat inzeráty, přiřazovat je k vyhledávacím dotazům pomocí různých shod klíčových slov a vykonávat všechny další činnosti, za které by jinak vyhledávač musel platit své zaměstnance. Geniální, což? Vymysleli to v Google a právě tohle je jedním z důvodů, proč Google světu vyhledávní nyní dominuje.
Stručně z historie vyhledávačů
Pradávná historie „válek vyhledávačů“ už dnes není pro marketéry zrovna aktuální. Uvádím ji tu spíše pro zajímavost, abyste si uměli alespoň trochu představit, jaké to bylo divoké období, kdy technologie vyhledávání teprve vznikaly. A kolik osobností, lidského umu i finančního kapitálu se tu protočilo, než svět drefinitivně opanoval Google. A týkalo se to i mnoha českých vyhledávačů.
Vyhledávače let devadesátých
- 1990 – vznikl první internetový vyhledávač jménem Archie. Naprogramoval ho Alan Emtage z univerzity v Montrealu. Archie uměl prohledávat FTP archívy a indexoval nalezené soubory pomocí příkazu grep, který funguje v operačním systému Unix. Prohledávání FTP bylo důležité, protože tehdy ještě neexistovaly webové stránky v současné podobě.
- 1993 – vznikají první webové stránky v HTML, prohlížeč Mosaic a s nimi i první vyhledávače indexující webové stránky, například Aliweb, JumpStation a WWW Worm. Indexovaly však pouze URL a hlavičku stránky.
- 1994 – založen internetový portál Yahoo! Zpočátku pouhý seznam oblíbených odkazů autorů, jimiž byli Jerry Yang a David Filo ze Standfordské univerzity. O rok později představili Yahoo Search, který se rychle stal prvním skutečně populárním vyhledávačem na světovém internetu.
- 1995 – vzniká internetový vyhledávač Excite, který jako první stojí na principu robota procházejícího web přes odkazy a indexujícího celý obsah stránky. Tento robot se jmenoval WebCrawler a vytvořil ho o rok dříve Brian Pinkerton z Washingtonské univerzity.
- 1996 – Ivo Lukačovič zakládá český portál Seznam.cz. Ten nejdříve sloužil jako seznam a katalog odkazů, o rok později už funguje jako fulltextový vyhledávač (ale dodávaný externě, na technologiích Kompas, AltaVista, Google nebo Jyxo).
- 1998 – Larry Page a Sergej Brin při studiu na Standfordské univerzitě zakládají současný největší vyhledávač Google. Ten se od otatních lišil řazením výsledků podle tzv. PageRanku, rankovacího algoritmu, který výrazně zvýšil relevanci výsledků hledání.
- 1999 – společnost Centrum Holdings, provozovatel portálu Centrum.cz, tehdy druhého největšího českého portálu, spouští vyhledávač zaměřený na české weby. Ten později dostal jméno Morfeo a sloužil zde až do roku 2011.
- 2000 – vyhledávač Google spouští reklamní systém AdWords a přidává tak do výsledků vyhledávání placenou reklamu (zpočátku placenou měsíčně, nikoliv jako PPC). Seznam spouští vlastní mapy (dnes známé jako Mapy.cz).
Webové vyhledávače po roce 2000
- 2002 – Michal Illich zakládá Jyxo, na svou dobu výborný český internetový vyhledávač, který například uměl opravovat překlepy, skloňovat a časovat česká slova, vyhledávat v PDF souborech či obrázcích. Kromě dříve zmiňovaného vyhledávání na Seznam.cz poháněl i hledání na Altas.cz, což byl ve své době třetí největší český portál. Vyhledávač Jyxo fungoval až do roku 2013.
- 2004 – Google kupuje australskou firmu Where 2 Technologies, jejíž program, který si lidé původně museli stáhnout do počítače, modifikuje na prvotní základ Google Maps. Během let 2004–2006 koupil Google několik dalších firem, které Google Maps obohatily např. o funkce Google Earth či funkci zobrazování dopravy v reálném čase.
- 2005 – Seznam po experimentech s externě dodávanými vyhledávači nasazuje první internetový vyhledávač Seznam Fulltext postavený na interním vývoji. Stejnou cestou jde vyhledávač MSN, za kterým stojí Microsoft a který dříve zobrazoval výsledky vyhledávače Yahoo.
- 2006 – Seznam spouští po vzoru Google reklamní systém Sklik a v jeho dalším vývoji se vydává logickou cestou kopírování nejdůležitějších funkcí z Google AdWords (což usnadňuje správu PPC kampaní provozovaných na obou systémech).